
{kind=link}
meta tiene liberado la última entrada en su serie Llama de modelos de IA generativa de código abierto: Llama 3. O, más exactamente, la compañía ha abierto dos modelos en su nueva familia Llama 3, y el resto llegará en una fecha futura no especificada.
Meta describe los nuevos modelos (Llama 3 8B, que contiene 8 mil millones de parámetros, y Llama 3 70B, que contiene 70 mil millones de parámetros) como un “gran salto” en comparación con los modelos Llama de la generación anterior, Llama 2 8B y Llama 2 70B. En cuanto al rendimiento. (Los parámetros definen esencialmente la habilidad de un modelo de IA en un problema, como analizar y generar texto; los modelos con un mayor número de parámetros son, en términos generales, más capaces que los modelos con un menor número de parámetros). De hecho, Meta dice que, por ejemplo, sus respectivos recuentos de parámetros, Llama 3 8B y Llama 3 70B – entrenados en dos clústeres de 24.000 GPU personalizados, están se encuentran entre los modelos de IA generativa de mejor rendimiento disponibles en la actualidad.
Es una gran afirmación. Entonces, ¿cómo lo apoya Meta? Bueno, la compañía señala las puntuaciones de los modelos Llama 3 en puntos de referencia de IA populares como MMLU (que intenta medir el conocimiento), ARC (que intenta medir la adquisición de habilidades) y DROP (que prueba el razonamiento de un modelo sobre fragmentos de texto). Como hemos escrito antes, la utilidad (y validez) de estos puntos de referencia es objeto de debate. Pero para bien o para mal, siguen siendo una de las pocas formas estandarizadas mediante las cuales los jugadores de IA como Meta evalúan sus modelos.
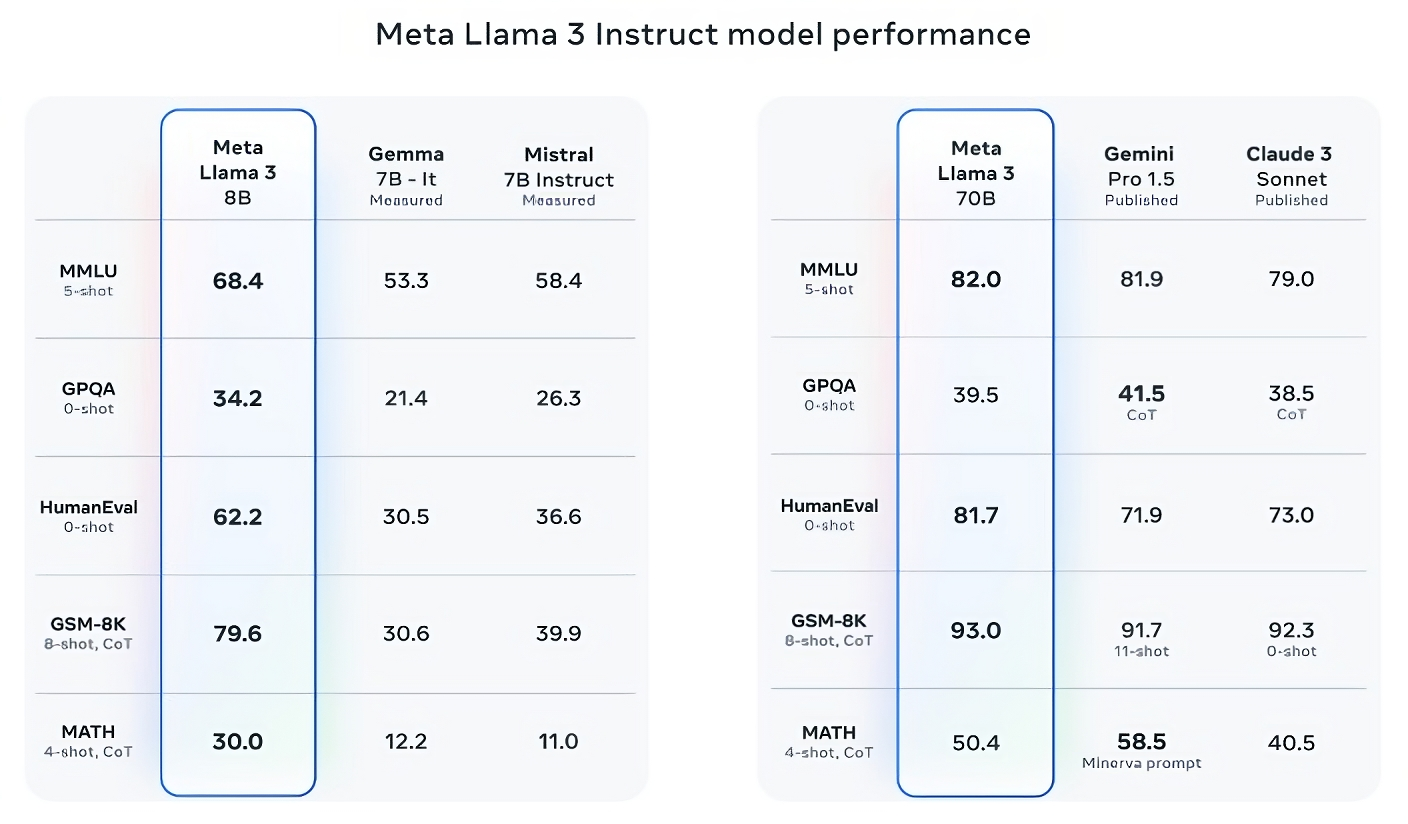
Llama 3 8B supera a otros modelos de código abierto como Mistral 7B de Mistral y Gemma 7B de Google, los cuales contienen 7 mil millones de parámetros, en al menos nueve puntos de referencia: MMLU, ARC, DROP, GPQA (un conjunto de biología, física y química). preguntas relacionadas), HumanEval (una prueba de generación de código), GSM-8K (problemas escritos de matemáticas), MATH (otro punto de referencia de matemáticas), AGIEval (un conjunto de pruebas de resolución de problemas) y BIG-Bench Hard (una evaluación de razonamiento de sentido común).
Ahora, Mistral 7B y Gemma 7B no están exactamente a la vanguardia (Mistral 7B se lanzó en septiembre pasado), y en algunos de los puntos de referencia que cita Meta, Llama 3 8B obtiene solo unos pocos puntos porcentuales más que cualquiera de los dos. Pero Meta también afirma que el modelo Llama 3 con mayor número de parámetros, Llama 3 70B, es competitivo con los modelos emblemáticos de IA generativa, incluido el Gemini 1.5 Pro, el último de la serie Gemini de Google.
Créditos de imagen: Meta
Llama 3 70B supera a Gemini 1.5 Pro en MMLU, HumanEval y GSM-8K y, aunque no rivaliza con el modelo más potente de Anthropic, Claude 3 Opus, Llama 3 70B obtiene una puntuación mejor que el modelo más débil de la serie Claude 3, Claude 3. Sonnet, en cinco puntos de referencia (MMLU, GPQA, HumanEval, GSM-8K y MATH).
Créditos de imagen: Meta
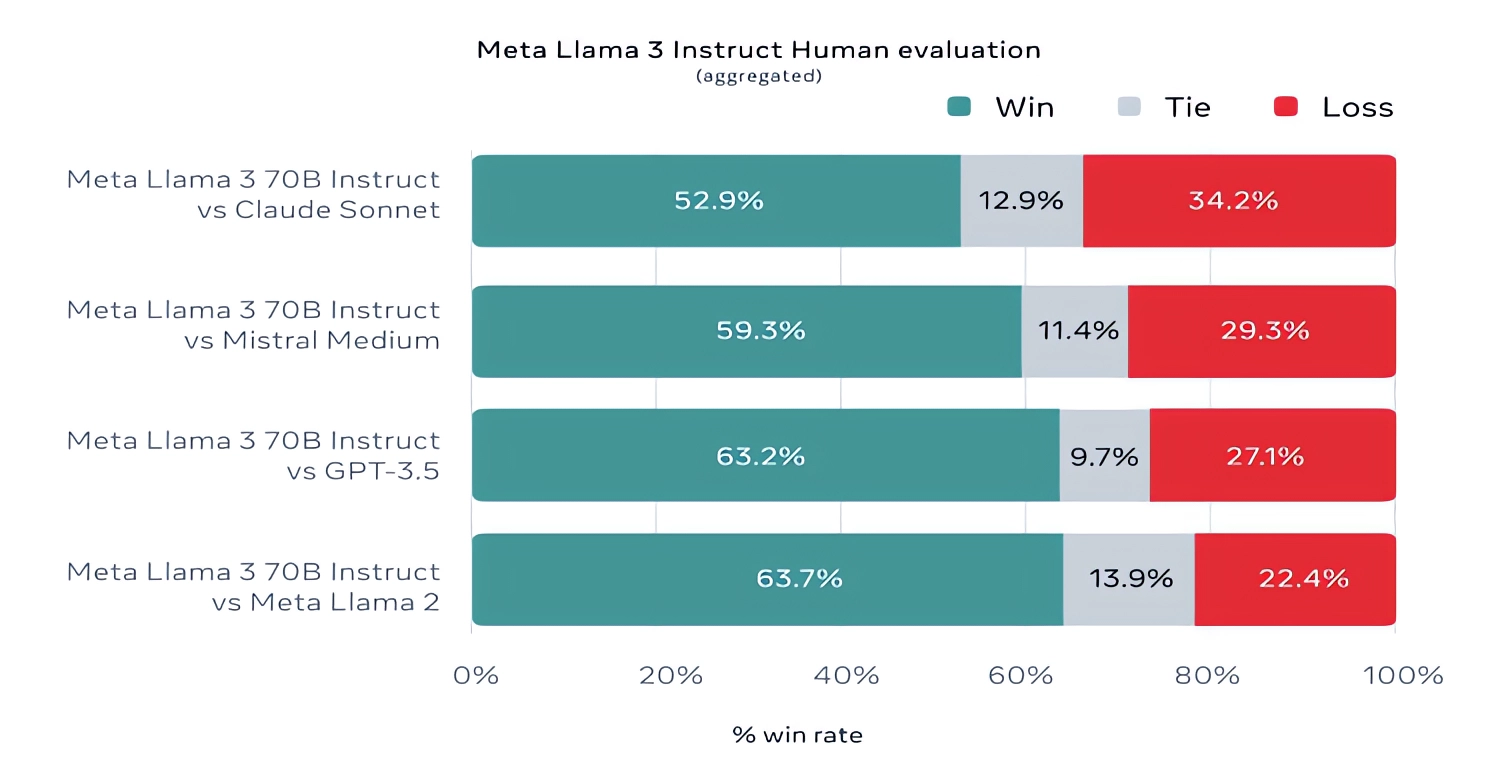
Por si sirve de algo, Meta también desarrolló su propio conjunto de pruebas que cubre casos de uso que van desde la codificación y la creación de escritos hasta el razonamiento y el resumen, y ¡sorpresa! — Llama 3 70B venció al modelo Mistral Medium de Mistral, GPT-3.5 de OpenAI y Claude Sonnet. Meta dice que impidió que sus equipos de modelos accedieran al set para mantener la objetividad, pero obviamente, dado que Meta mismo ideó la prueba, los resultados deben tomarse con cautela.
Créditos de imagen: Meta
Desde un punto de vista más cualitativo, Meta dice que los usuarios de los nuevos modelos Llama deberían esperar más “dirigibilidad”, una menor probabilidad de negarse a responder preguntas y una mayor precisión en preguntas de trivia, preguntas relacionadas con la historia y los campos STEM, como la ingeniería, la ciencia y la codificación general. recomendaciones. Esto se debe en parte a un conjunto de datos mucho más grande: una colección de 15 billones de tokens, o la alucinante cantidad de ~750.000.000.000 de palabras, siete veces el tamaño del conjunto de entrenamiento de Llama 2. (En el campo de la IA, “tokens” se refiere a bits subdivididos de datos sin procesar, como las sílabas “fan”, “tas” y “tic” en la palabra “fantástico”).
¿De dónde vinieron estos datos? Buena pregunta. Meta no lo dijo, revelando solo que se basó en “fuentes disponibles públicamente”, incluyó cuatro veces más código que en el conjunto de datos de entrenamiento de Llama 2 y que el 5% de ese conjunto tiene datos que no están en inglés (en ~30 idiomas). para mejorar el rendimiento en idiomas distintos del inglés. Meta también dijo que utilizó datos sintéticos, es decir, datos generados por IA, para crear documentos más largos para que los modelos Llama 3 puedan entrenar. un enfoque algo controvertido debido a los posibles inconvenientes de rendimiento.
“Si bien los modelos que lanzamos hoy solo están ajustados para los resultados en inglés, la mayor diversidad de datos ayuda a los modelos a reconocer mejor los matices y patrones, y a desempeñarse con fuerza en una variedad de tareas”, escribe Meta en una publicación de blog compartida con TechCrunch.
Muchos proveedores de IA generativa ven los datos de entrenamiento como una ventaja competitiva y, por lo tanto, los mantienen junto con la información correspondiente cerca del cofre. Pero los detalles de los datos de capacitación también son una fuente potencial de demandas relacionadas con la propiedad intelectual, otro desincentivo para revelar mucho. Informes recientes reveló que Meta, en su búsqueda por mantener el ritmo con sus rivales de IA, en un momento utilizó libros electrónicos con derechos de autor para el entrenamiento de IA a pesar de las advertencias de los propios abogados de la compañía; Meta y OpenAI son objeto de una demanda en curso presentada por autores, incluida la comediante Sarah Silverman, por el presunto uso no autorizado de datos protegidos por derechos de autor por parte de los proveedores para capacitación.
Entonces, ¿qué pasa con la toxicidad y el sesgo, otros dos problemas comunes con los modelos de IA generativa?incluyendo llama 2)? ¿Llama 3 mejora en esas áreas? Sí, afirma Meta.
Meta dice que desarrolló nuevos canales de filtrado de datos para mejorar la calidad de los datos de entrenamiento de su modelo y que actualizó su par de suites de seguridad de IA generativa, Llama Guard y CybersecEval, para intentar evitar el uso indebido y las generaciones de texto no deseado de Llama. 3 modelos y otros. La compañía también está lanzando una nueva herramienta, Code Shield, diseñada para detectar código de modelos generativos de IA que podrían introducir vulnerabilidades de seguridad.
Sin embargo, el filtrado no es infalible y herramientas como Llama Guard, CybersecEval y Code Shield solo llegan hasta cierto punto. (Ver: La tendencia de Llama 2 a inventar respuestas a preguntas y filtrar información privada de salud y financiera.) Tendremos que esperar y ver cómo se desempeñan los modelos Llama 3 en la naturaleza, incluidas las pruebas realizadas por académicos en puntos de referencia alternativos.
Meta dice que los modelos Llama 3, que ya están disponibles para descargar y que impulsan el asistente Meta AI de Meta en Facebook, Instagram, WhatsApp, Messenger y la web, pronto se alojarán en forma administrada en una amplia gama de plataformas en la nube, incluida AWS. Databricks, Google Cloud, Hugging Face, Kaggle, WatsonX de IBM, Microsoft Azure, NIM de Nvidia y Snowflake. En el futuro también estarán disponibles versiones de los modelos optimizados para hardware de AMD, AWS, Dell, Intel, Nvidia y Qualcomm.
Y hay modelos más capaces en el horizonte.
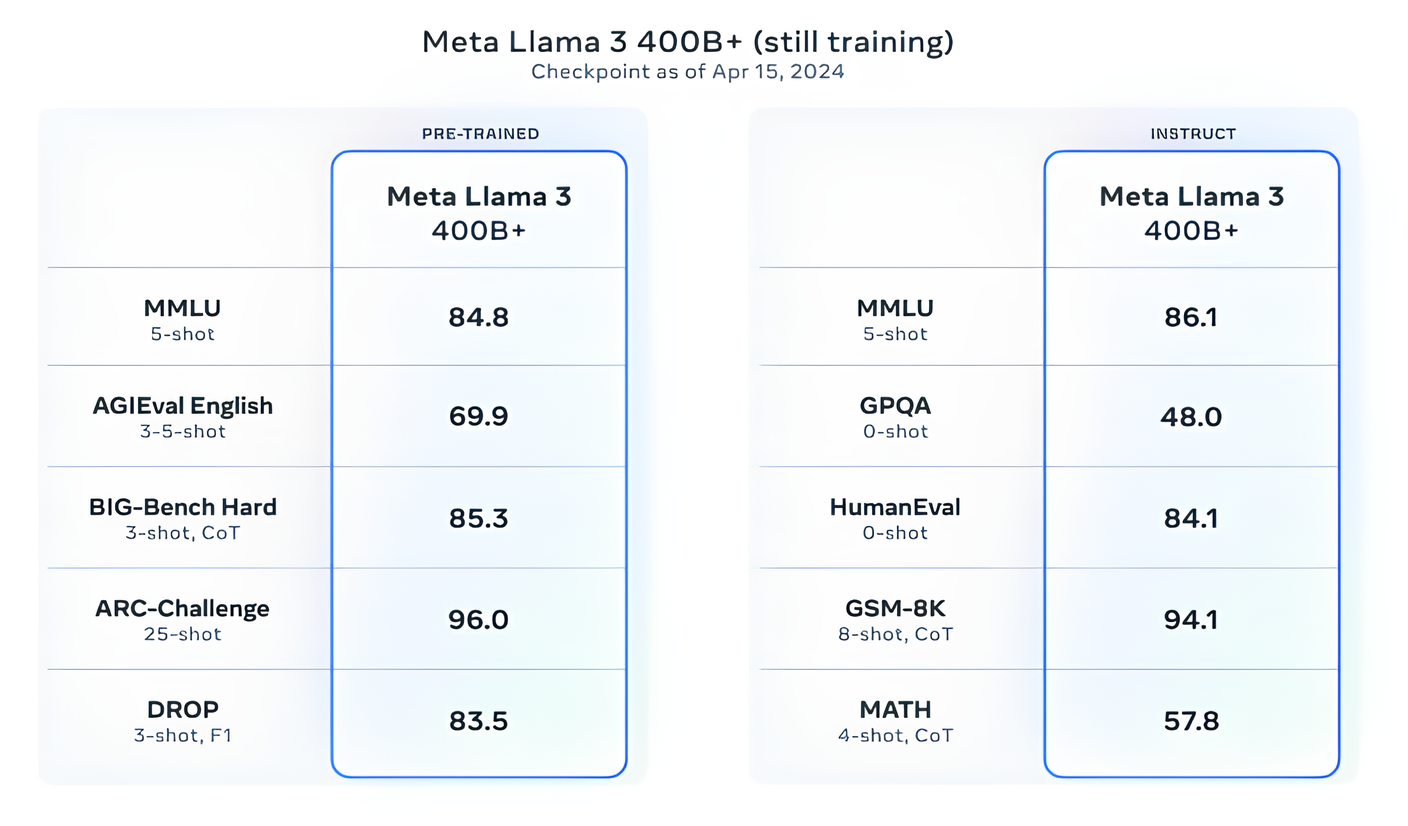
Meta dice que actualmente está entrenando modelos Llama 3 con más de 400 mil millones de parámetros de tamaño: modelos con la capacidad de “conversar en múltiples idiomas”, tomar más datos y comprender imágenes y otras modalidades, así como texto, lo que traería la serie Llama 3. en línea con lanzamientos abiertos como el de Hugging Face Idéficas2.
Créditos de imagen: Meta
“Nuestro objetivo en el futuro cercano es hacer que Llama 3 sea multilingüe y multimodal, tenga un contexto más amplio y continúe mejorando el rendimiento general en todos los aspectos principales. [large language model] capacidades como el razonamiento y la codificación”, escribe Meta en una publicación de blog. “Hay mucho más por venir”.
En efecto.