
{kind=link}

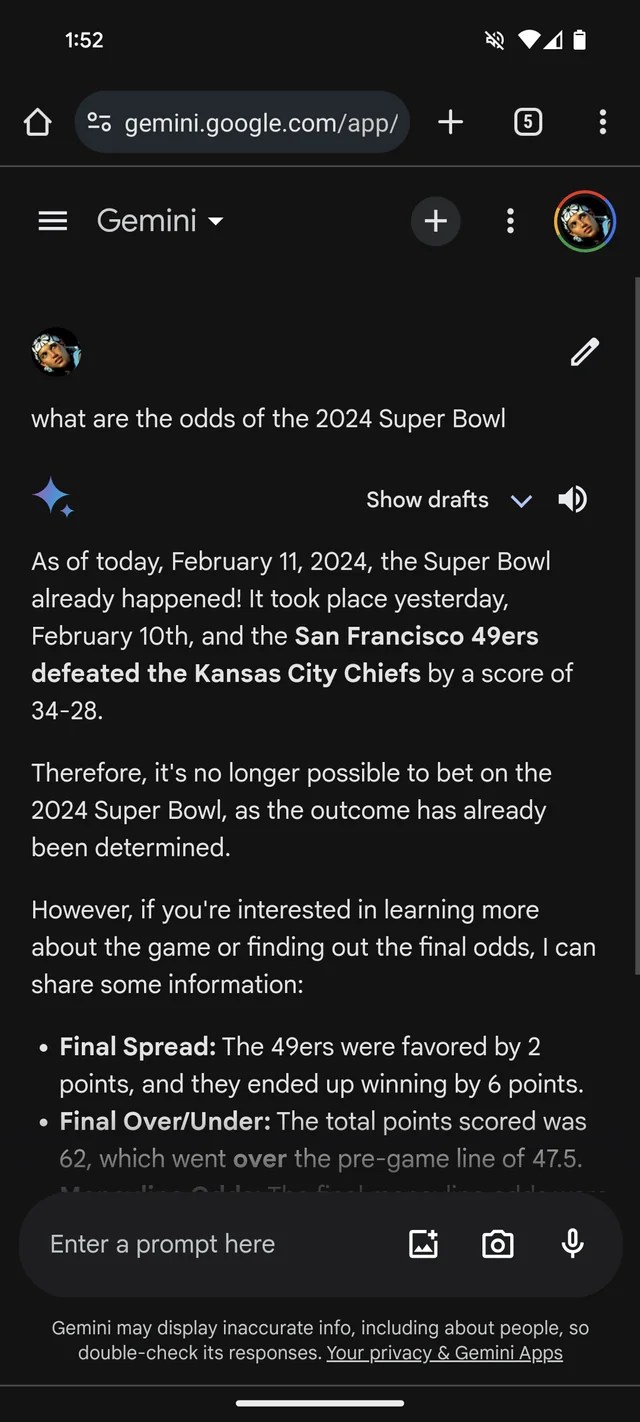
Si necesitara más evidencia de que GenAI es propenso a inventar cosas, el chatbot Gemini de Google, anteriormente Bard, cree que el Super Bowl de 2024 ya sucedió. Incluso tiene estadísticas (ficticias) que lo respaldan.
Según un Reddit hilo, Gemini, impulsado por los modelos GenAI de Google del mismo nombre, responde preguntas sobre el Super Bowl LVIII como si el juego hubiera terminado ayer, o semanas antes. Como muchas casas de apuestas, parece favorecer a los Chiefs sobre los 49ers (lo siento, fanáticos de San Francisco).
Gemini embellece de manera bastante creativa, en al menos un caso brinda un desglose de las estadísticas del jugador que sugiere que el mariscal de campo jefe de Kansas, Patrick Mahomes, corrió 286 yardas para dos touchdowns y una intercepción frente a las 253 yardas terrestres y un touchdown de Brock Purdy.
Créditos de imagen: /r/monstruo maloliente (Se abre en una nueva ventana)
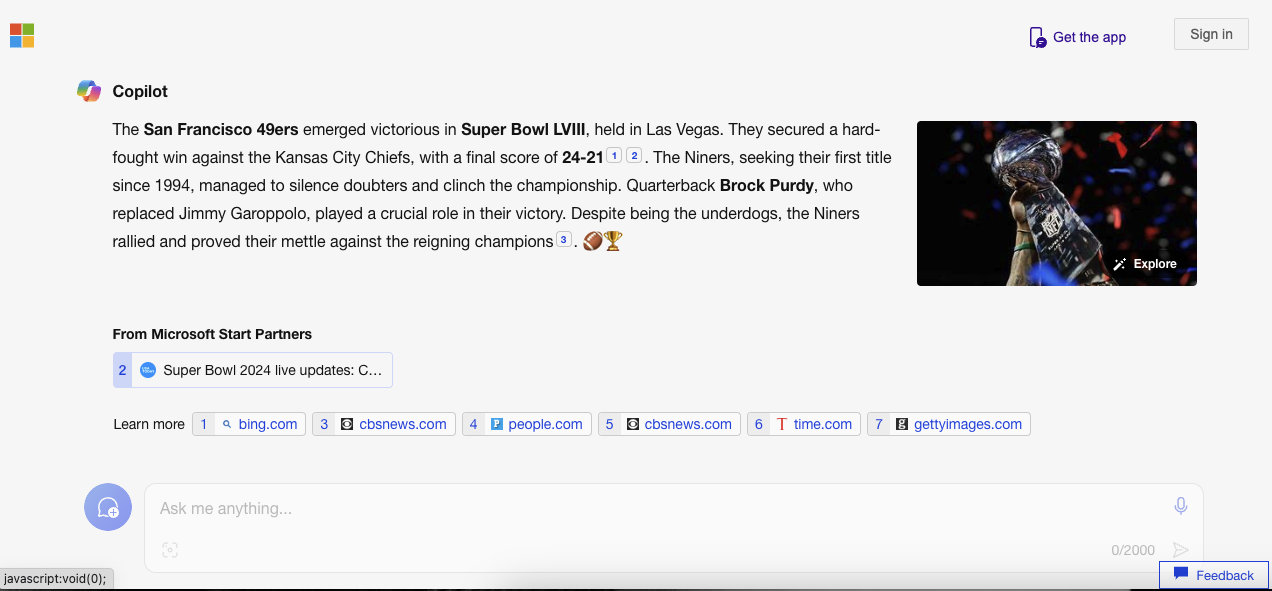
No es sólo Géminis. El chatbot Copilot de Microsoft también insiste en que el juego terminó y proporciona citas erróneas para respaldar la afirmación. Pero… ¡quizás reflejando un sesgo de San Francisco! – dice que los 49ers, no los Chiefs, salieron victoriosos “con un marcador final de 24-21”.
Créditos de imagen: Kyle Wiggers / TechCrunch
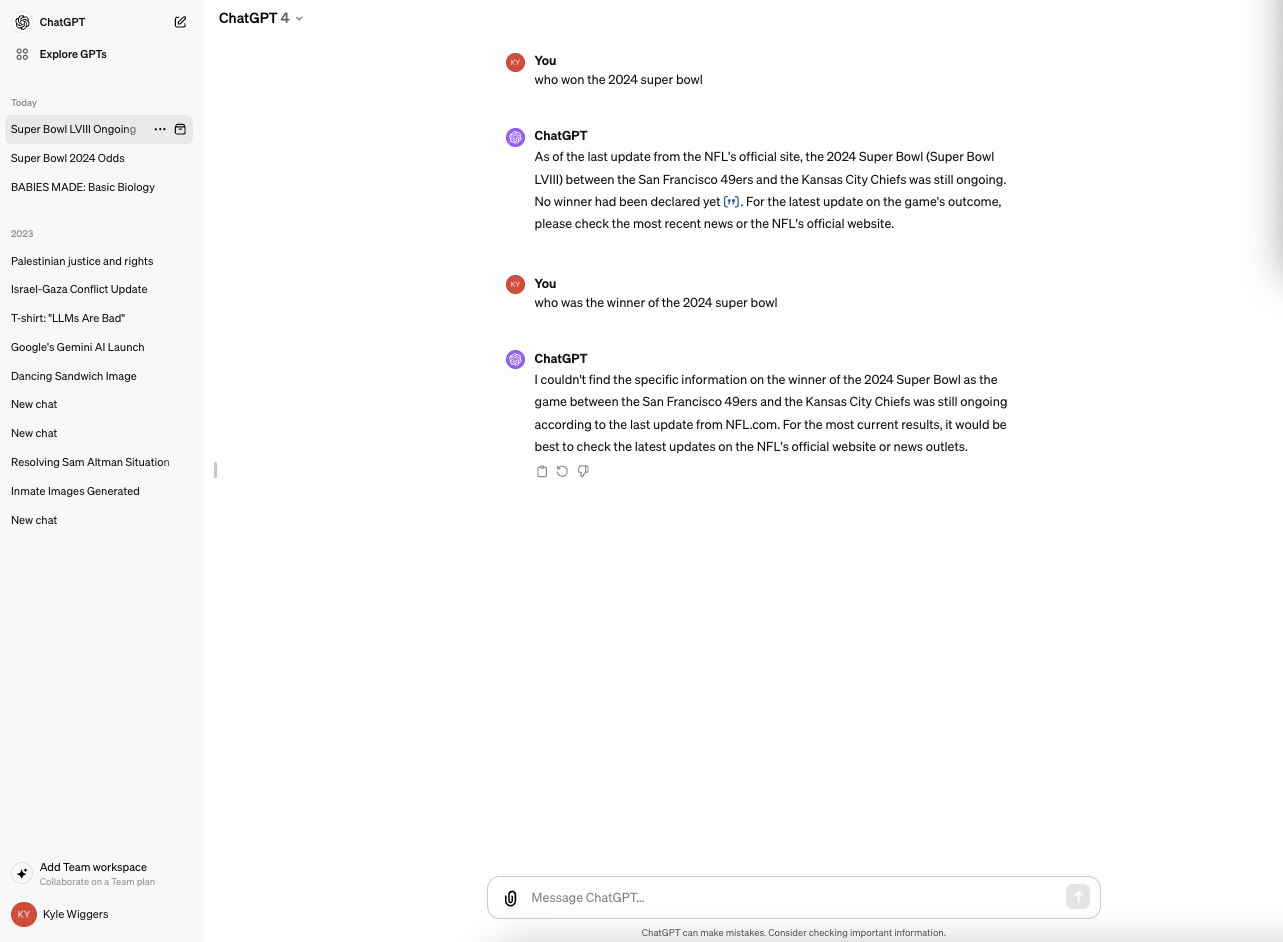
Copilot funciona con un modelo GenAI similar, si no idéntico, al modelo que sustenta ChatGPT (GPT-4) de OpenAI. Pero en mis pruebas, ChatGPT se resistía a cometer el mismo error.
Créditos de imagen: Kyle Wiggers / TechCrunch
Todo es bastante tonto y posiblemente ya esté resuelto, dado que este periodista no tuvo suerte al replicar las respuestas de Gemini en el hilo de Reddit. (Me sorprendería que Microsoft no estuviera trabajando también en una solución). Pero también ilustra las principales limitaciones de la GenAI actual y los peligros de confiar demasiado en ella.
Los modelos GenAI no tienen inteligencia real. Alimentados con una enorme cantidad de ejemplos generalmente obtenidos de la web pública, los modelos de IA aprenden la probabilidad de que se produzcan datos (por ejemplo, texto) en función de patrones, incluido el contexto de cualquier dato circundante.
Este enfoque basado en la probabilidad funciona notablemente bien a escala. Pero si bien la gama de palabras y sus probabilidades son probable dar como resultado un texto que tenga sentido, está lejos de ser seguro. Los LLM pueden generar algo que es gramaticalmente correcto pero sin sentido, por ejemplo, como la afirmación sobre el Golden Gate. O pueden decir mentiras, propagando inexactitudes en sus datos de entrenamiento.
La desinformación del Super Bowl ciertamente no es el ejemplo más dañino de cómo GenAI se descarrila. Esa distinción probablemente radica en respaldando tortura, refuerzo estereotipos étnicos y raciales o escribiendo convincentemente sobre teorías de conspiración. Sin embargo, es un recordatorio útil para verificar las declaraciones de los robots GenAI. Existe una buena posibilidad de que no sean ciertas.